7. The fragmented global landscape for anonymization
Data law trends 2026
In brief
Around the world, anonymization is coming under intense legal and regulatory pressure. As organizations increasingly want to leverage data to power AI, analytics and global collaborations, the rules on what truly counts as anonymized data are shifting fast – and expectations are rising. Courts and regulators are challenging outdated or over-broad claims that data can no longer be linked to individuals, pushing companies to adopt more robust, context-sensitive approaches. Recent decisions in Europe and stepped-up actions from regulators like the US Federal Trade Commission (FTC) make clear that half-measures don’t work – and carry real legal and reputational risks. In this environment, effective anonymization is no longer a technical detail; it’s a baseline.
![]()
Using inadequate anonymization methods or overstating anonymization processes carries significant compliance and reputational risks.
Giles Pratt, Partner
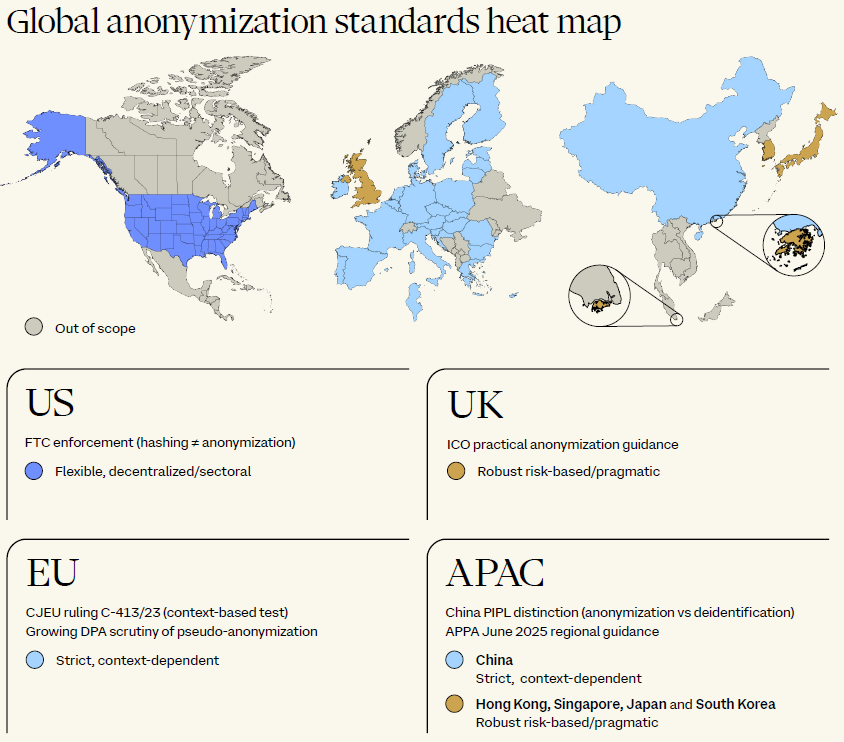
Fragmented global standards for anonymization
Anonymization is essential for organizations seeking to use personal data for innovation and secondary purposes while minimizing privacy risk and compliance obligations, including under additional sector-specific regulation. But for multinationals, the absence of global alignment creates a patchwork of obligations that increases legal risk, drives up compliance costs and complicates cross-border data use.
The trend – especially in the EU – is towards a more nuanced, context-specific test of when data is truly anonymized, with recent court pronouncements adding further layers of complexity.
- EU: The EU’s General Data Protection Regulation (GDPR) doesn’t define 'anonymization,’ but Recital 26 makes clear that anonymous information falls outside its scope. The key question is whether data ‘relates to an identified or identifiable natural person.’ Courts initially took a strict view, asking whether anyone could, in principle, identify the individual. Recent case law, including SRB v EDPS (Court of Justice of the EU (CJEU) case C-413/23 P), signals a shift towards a more pragmatic understanding. Whether information is considered personal data must be assessed in context, based on the means reasonably available to the respective actor (data provider or recipient), rather than to hypothetical others.
- UK: The UK GDPR and the Data Protection Act 2018 also stop short of defining ‘anonymization.’ The line is instead drawn by reference to the definition of personal data. The Information Commissioner’s Office provides practical guidance, describing anonymization as ‘the techniques and approaches you can use to prevent identifying people that the data relates to,’ and referring to ‘effective anonymization’ when the UK GDPR threshold is met through robust technical and organizational measures.
- US: In the US, ‘deidentification’ is the term typically used, and definitions vary across a patchwork of state and sectoral laws. The California Consumer Privacy Act defines deidentified data as data that cannot reasonably be linked to a consumer, provided the business: (i) takes reasonable measures to prevent reidentification; (ii) publicly commits not to reidentify the data; and (iii) requires recipients to uphold deidentification requirements. Additional frameworks, like the Health Insurance Portability and Accountability Act (HIPAA), add complexity, offering both a ‘Safe Harbor’ method (removal of 18 identifiers) and an ‘Expert Determination’ method (statistical assessment of reidentification risk).
- APAC: Standards for anonymization vary significantly across the region:
- China: The Personal Information Protection Law (PIPL) distinguishes between anonymization (irreversible, non-restorable data) and de-identification (reversible, potentially identifiable when combined with other data). A national anonymization standard is under development.
- Japan: Data is considered anonymized if it cannot be restored using methods available to ordinary people or businesses, assessed case-by-case and in context.
- Singapore: Guidelines allow both reversible and irreversible anonymization, with emphasis on assessing the likelihood of reidentification in practice.
- Hong Kong: Focuses on practical risk: could an individual reasonably and practically be re-identified, including using other publicly available information?
- South Korea: The Personal Information Protection Act now delineates anonymized and pseudonymized data, and detailed guidelines on pseudonymization have been published.
- Regional Guidance: In June 2025, the Technology Working Group of the Asia Pacific Privacy Authorities published its Guide to Getting Started with Anonymization, aiming to align approaches across the region. It defines anonymization as rendering personal data unidentifiable (alone or in combination with other data) using reasonable and state-of-the-art measures, and recommends best-practice techniques such as suppression, masking, generalization, noise addition, sampling and swapping, drawing on international standards such as ISO/IEC 20889 and risk-assessment methods like k-anonymity.
![]()
Standards for anonymization vary across the globe. Special care needs to be taken with aggregations of data from multiple country sources.
Richard Bird, Partner
Rising regulatory enforcement around misleading anonymization claims
Regulators are increasingly targeting misleading or overstated claims of anonymization. In the US, the FTC has shown particular interest in pursuing companies that rely on weak deidentification measures or misrepresent their practices. Its guidance, ‘No, hashing still doesn’t make your data anonymous,’ makes clear that techniques such as hashing – which converts personal data into unique strings – fall short of true anonymization. Such methods can still leave individuals re-identifiable, particularly when hashes are matched or combined with other information. The FTC has already brought enforcement actions against companies on this basis.
Internationally, regulators are scrutinizing purported anonymization that fails to meet legal or technical standards, with growing attention on whether datasets can be realistically reidentified given advances in analytics and the availability of external data.
Best practice is moving towards comprehensive risk assessment and stronger governance of anonymized datasets. Keeping detailed records, testing reidentification risk on an ongoing basis and updating governance to reflect evolving guidance and technology are now critical.
Anonymization as a strategic enabler of AI and global data flows
For global organizations, anonymization is no longer just a compliance exercise; it is a strategic tool for responsible innovation in AI, machine learning, advanced analytics and cross-border data collaborations.
Properly anonymized datasets – where individuals cannot reasonably be reidentified – usually fall outside the scope of data protection regimes such as the EU GDPR, and cross-border data transfer frameworks (including Standard Contractual Clauses, Cross-Border Privacy Rules, and adequacy decisions). That exemption reduces compliance pressure and clears the way for international data-driven initiatives. Although anonymization does not exclude the application of frameworks like the EU AI Act, it simplifies AI compliance significantly.
But advances in technology – from the growing sophistication of AI to the sheer volume of external data now available – have raised the bar. Traditional techniques are increasingly vulnerable to reidentification, making anonymization a dynamic, context-specific discipline rather than a one-off fix. New approaches are emerging, from synthetic data generation to privacy-enhancing technologies (PETs) and federated learning. These solutions allow organizations to train AI models and extract value from data while keeping privacy risks – and regulatory exposure – in check.
![]()
Anonymization is a strategic enabler for global data innovation.
Mark Egeler, Partner
Sector-specific relevance and compliance use cases
Anonymization plays a decisive role across industries, balancing innovation with legal limits:
- Healthcare/Pharma: Anonymized patient data underpins secondary research and collaboration despite strict rules on clinical trial and health information.
- Financial Services: Institutions anonymize transactional data to power AI driven fraud detection, risk modeling and market analytics, while staying within strict privacy boundaries.
- Technology & Media: These sectors rely on behavioral analytics for product development but must draw a clear line between pseudonymization and full anonymization to remain compliant, particularly under the GDPR and emerging AI regulations.
In each case, the ability to robustly demonstrate that data is genuinely anonymized not only reduces legal risk but also opens the door to new forms of data use.
Looking ahead
Effective anonymization is no longer a one-off technical fix but an ongoing governance priority – central to unlocking AI, advanced analytics and cross-border data flows while keeping pace with fast-changing laws. Here’s what organizations should do now:
- Re-evaluate processes: Regularly test anonymization and deidentification methods against new laws, court rulings and technological advances. Ensure that your approaches – whether hashing, aggregation, masking or more advanced techniques – meet current standards and withstand scrutiny.
- Build strong governance: Treat anonymization as a dynamic process. Put in place governance frameworks, continuous reidentification risk assessments and periodic audits. Document your methodologies and decision-making – regulators increasingly expect you to show your work.
- Adopt new tools: Explore synthetic data, federated learning and other PETs to balance utility with protection. Combine technical and organizational controls for maximum effect.
- Train and align: Make sure staff understand the distinction between anonymization and pseudonymization. Update privacy policies, contracts and data-sharing arrangements, and hold partners and vendors to the same standards.
- Monitor enforcement trends: Follow regulatory guidance and enforcement in your key markets. Be precise in disclosures – overstating anonymization is an emerging enforcement trigger.
Anonymization is complex, but it is also pivotal to building resilient, future-ready data strategies. Our global team helps organizations respond to regulatory change, from practical compliance assessments to detailed technical and legal reviews.